





《正则表达式测试器》是程序员高效学习RegEx的移动好帮手,具备实时测试、语法可视化功能,还支持中英双语界面。常用规则库,像IP、邮箱、密码等场景的规则都能一键调用,帮你快速掌握文本匹配和表单验证的技巧。不用再枯燥地死记硬背,让复杂的正则表达式变得直观易懂!
主界面:
像下图展示的那样,借助IPv4的正则表达式规则,可视化图形能让这些正则规则更具可读性。
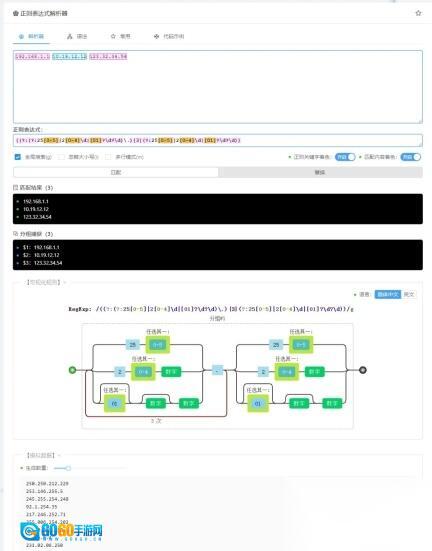
语法界面:
我花了很长时间整理正则语法规则,现在已经梳理得比较清晰了,相信大家多看几遍就能记住。
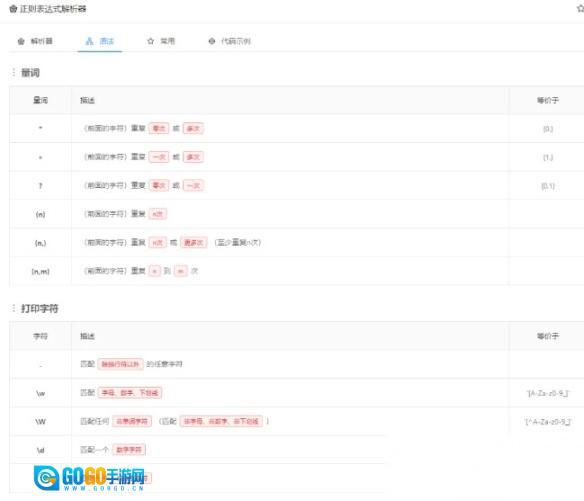
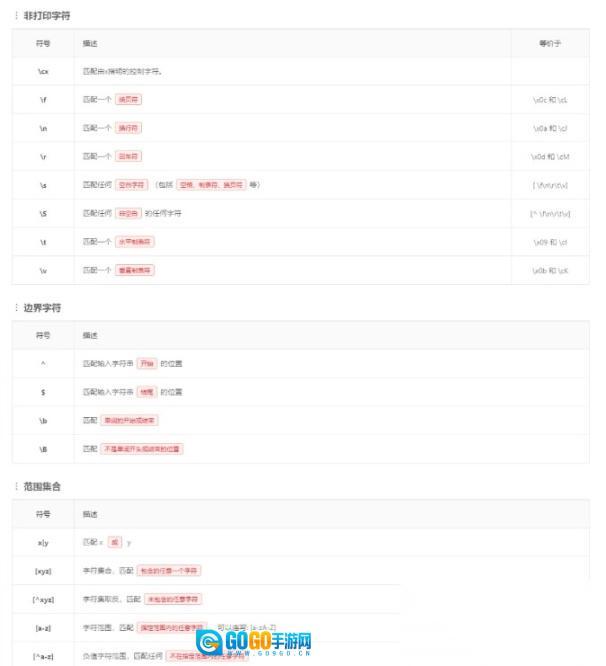


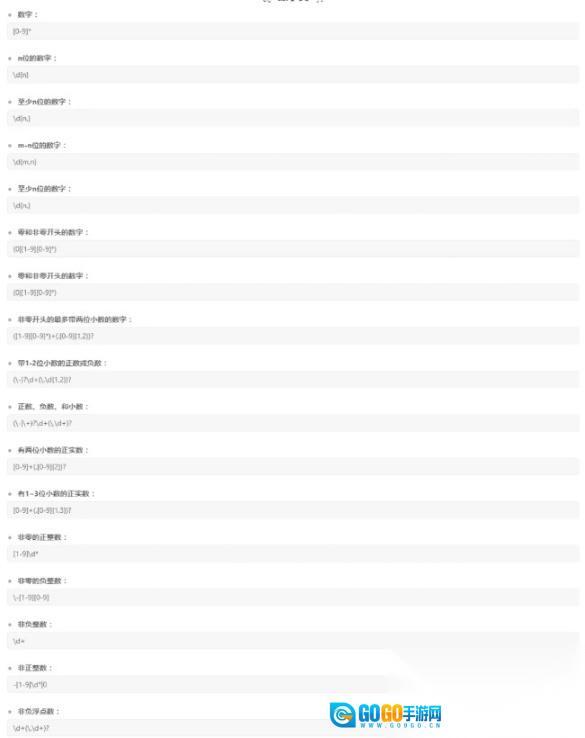
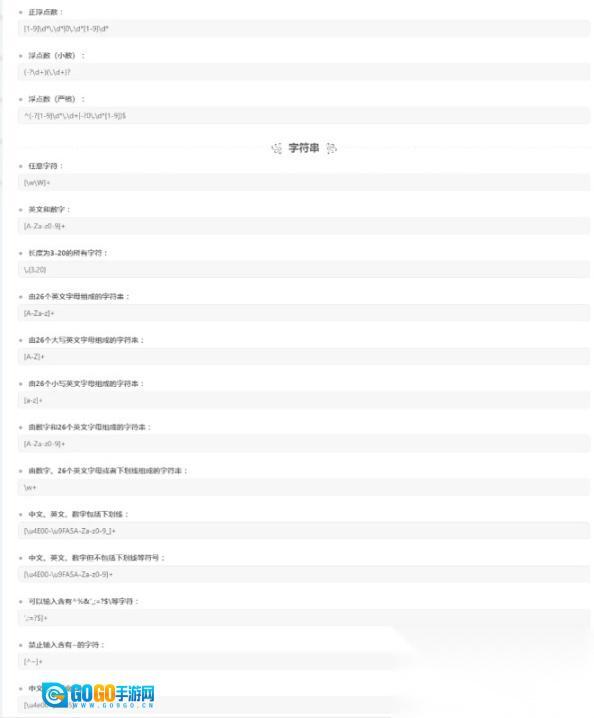
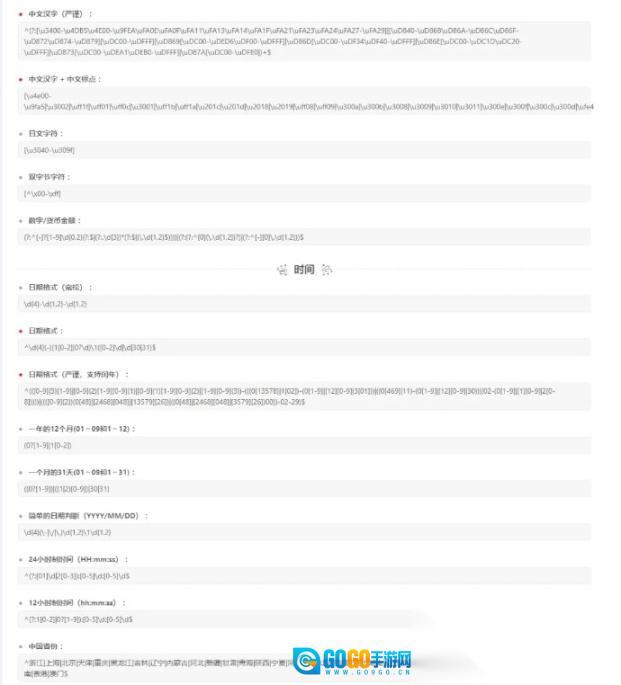
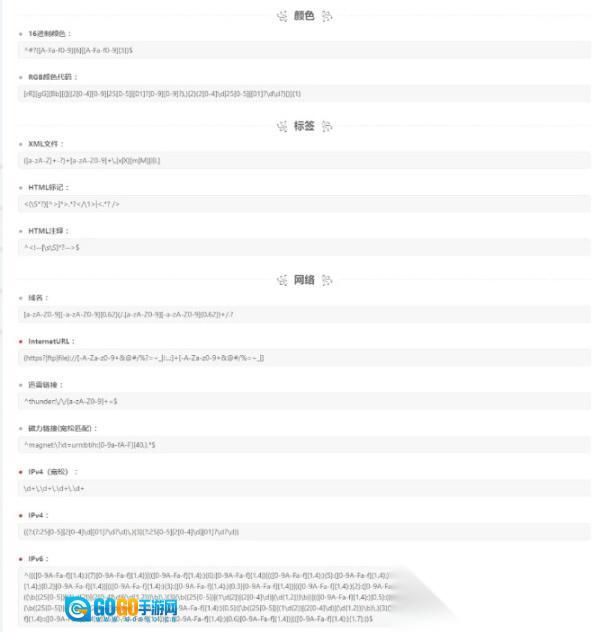
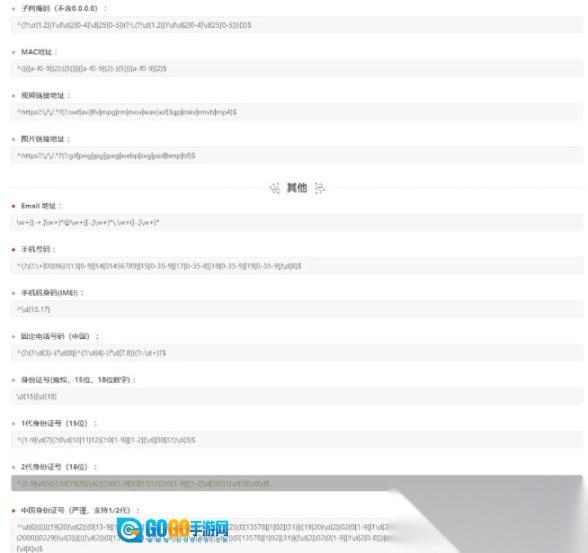
常用正则:
收录了常用的正则规则,可以
点击
解析quo一键使用
正则表达式,也叫规则表达式,(英文是Regular Expression,在代码里通常会简写成regex、regexp或者RE),这是一种文本模式,属于计算机科学领域的概念,里面包含普通字符(像a到z这样的字母)和特殊字符(这类特殊字符被称作“元字符”)。
正则表达式借助单一字符串来描述、匹配一系列契合特定句法规则的字符串,一般用于检索和替换那些符合某类模式(规则)的文本。
不少程序设计语言都支持借助正则表达式来开展字符串操作。
比如说,Perl 里面就了一个功能十分强大的正则表达式引擎。
正则表达式这一概念起初是通过Unix系统里的工具软件(像sed与grep这类)得到推广的,之后才慢慢在Scala、PHP、C#、Java、C++、Objective-c、Perl、Swift、VBScript、Javascript、Ruby和Python等众多编程语言中被广泛应用。
正则表达式一般缩写为“regex”,单数形式包括regexp、regex,复数形式则有regexps、regexes、regexen。
运行服务时,即便碰到像SSL问题这类小状况,也可以通过对运行命令的配置稍作调整来解决。
正则表达式里的“.”与“.?”,核心差异体现在匹配模式上,即前者采用贪婪匹配,后者采用非贪婪匹配。
贪婪匹配(.*):这种匹配方式会尽可能多地去匹配字符,一直到没有更多可匹配的字符才会停止。举个例子,在字符串“abcdefg”里,使用正则表达式“a.*g”进行匹配时,会把整个“abcdefg”字符串都匹配到12
非贪婪匹配(.*?):这种匹配方式会尽可能少地去匹配字符,只要找到能够满足整个模式的最小匹配内容,就会立刻停止匹配过程。
比如,在字符串“abcdefg”里,正则表达式“a.*?g”仅会匹配“abcdefg”当中的“abcdefg”这部分内容。
在编写处理字符串的程序或网页时,正则表达式相较于通配符,能更精准地满足查找符合复杂规则字符串的需求——例如snort规则里的pcre字段,就是通过正则表达式来实现的。对于偏好自主掌控的用户而言,由于这是开源项目,还可以把代码下载到本地,安装好依赖后运行服务;即便遇到SSL问题这类小状况,也能通过略微调整运行命令的配置来解决。
















